当我们从客户那里收集验证数据时,我们可以调整算法,使其对“有用的”异常更加敏感,而对多余的异常不那么敏感。反馈应该开始精确指出时间序列的哪些属性指向更有趣的异常。我们还可以进行A/B测试,向特定客户发布不同版本的算法,看看是否能获得更多好评。随着时间的推移,微小的改进可能导致显著的精度增益。



在本系列的第4部分中,我们将查看在实际加工环境中捕获的一些异常示例。然后我们将讨论如何将其投入生产。
我们确定了五种不同的异常类型。
示例1:前面的刀具故障
采用这种方法的最初目的是因为我们假设机器在失败之前会经历异常行为。我们记录了这种情况发生的几个案例——这里我们将简要描述一个示例案例。
凌晨2点25分发生了一次异常,3分钟后,凌晨2点28分发生了一次灾难性的工具故障。
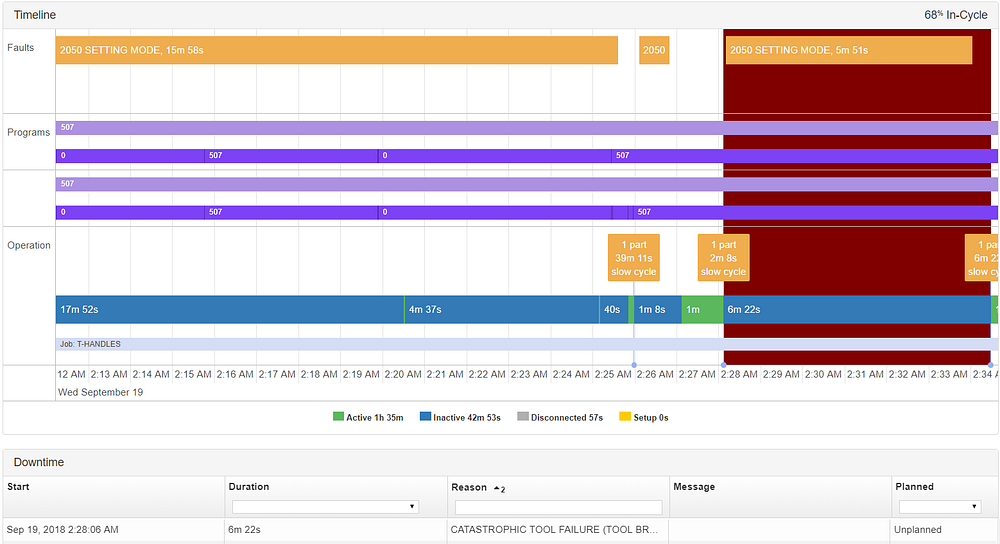
如果我们再深入一点,看看这部分有什么不同,我们就能很容易地想象出发生了什么。让我们从集群回溯到部件签名来诊断这个问题。
集群级别
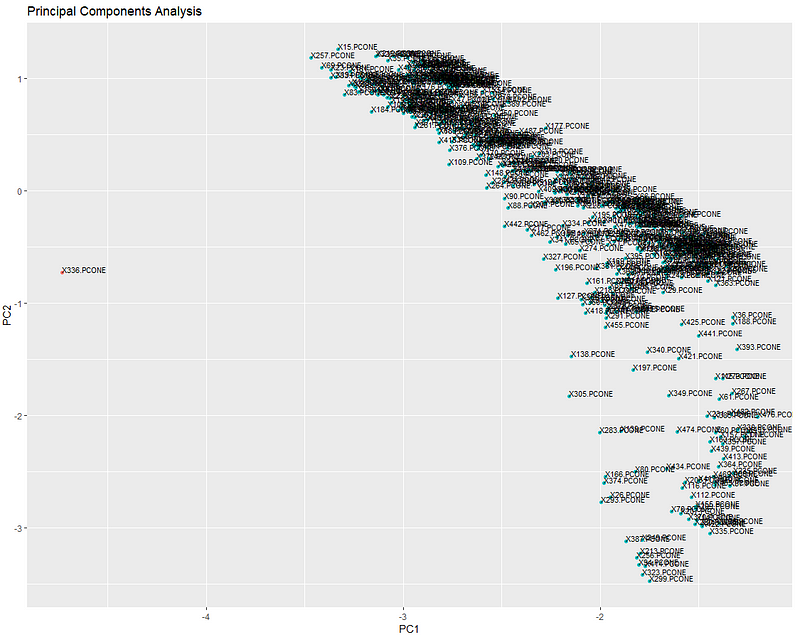
从晚上10点到早上6点,大约制造了450个零件。上图显示了当投影到一个2D平面上时,它们的部件特征的相对位置。就像我们在聚类层面上看到的,这里明显有一个异常。所有其他部分都聚集在一起,DBSCAN很容易分离出异常,独自漂浮在太空中。让我们再深入一层。
时间序列特性级别
上面的聚类图是由每个部分签名提取的时间序列特征生成的。让我们看看异常的特征相对于所有其他部分的位置(用紫色突出显示)。
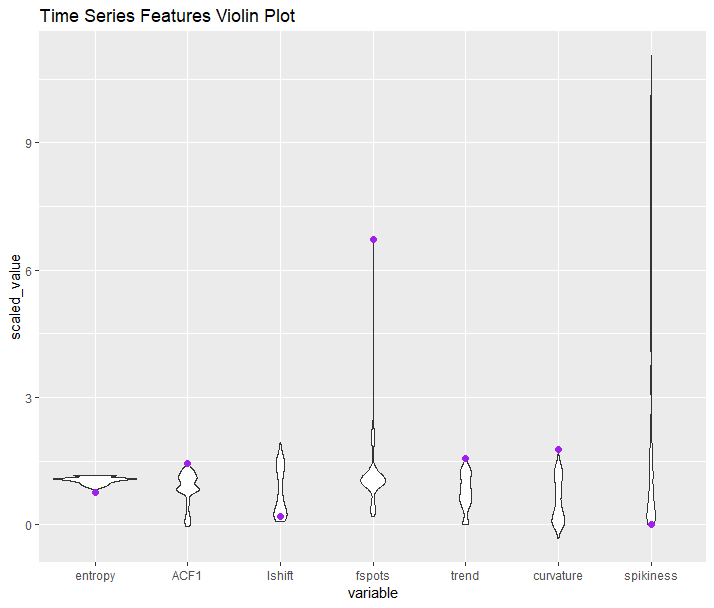
我们可以看到,我们的异常部分的所有特征都是这些指标的极端目的,这解释了为什么它从其他一切都偏远了。挖一个水平更深..
零件签名水平
与其他一切相比,这部分签名看起来像什么?下面我们在异常部分周围设置50份签名。再一次,它非常明显,其中一个异常值是。
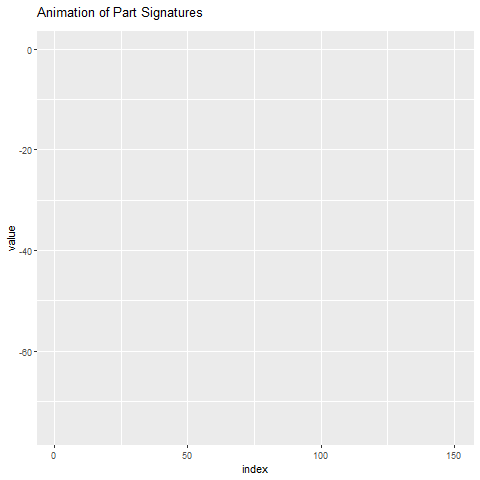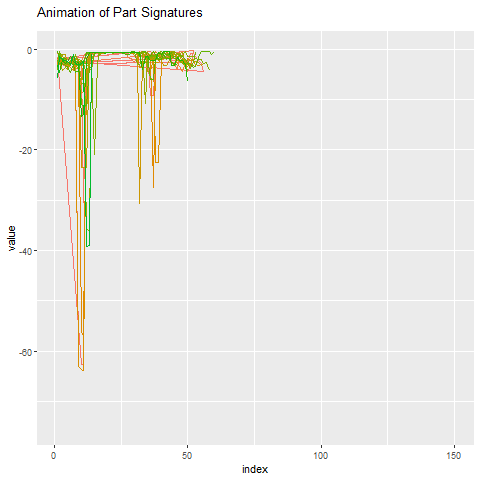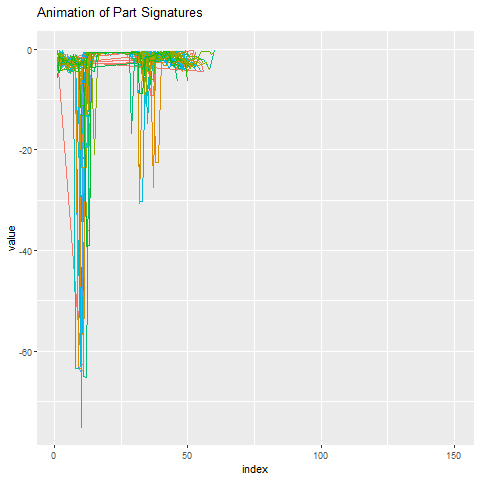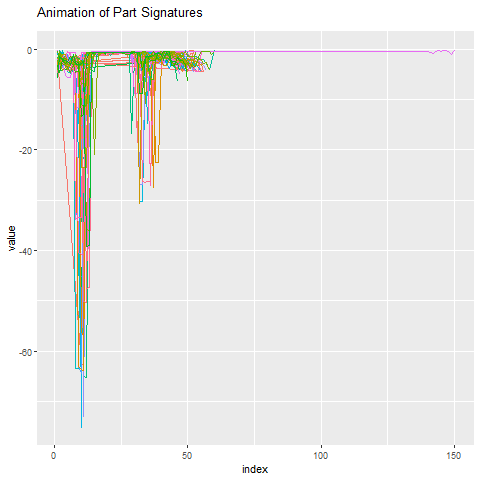
预测工具故障的含义是显着的。对于一个,通过节省运营商成本和工具更改,最小化停机和成本。它还可以让人知道,知道有一种浅视您的制造地板问题的算法。
例2:检测冷却剂
在这台机器上,9点39分发生了异常,紧接着“冷却液流出”警报响起。操作人员会在机器用完冷却剂之前立即得到通知。

一个人可能会问 - 如果我在几秒钟之后会出现警报,这是什么价值?
这里的附加价值是,运营商并不总是关注警报,通常只有在长时间停机后才会收到警报。操作员可以通过响应异常文本来减少机器的总停机时间,而不是让机器空闲直到他收到警报(或在走动时注意到它在空闲)。

例3:上述Barfeeder告警
在这个类别的最后一个例子中,操作员在“BAR FEEDER报警”前6分钟收到警报,时间是早上6:23.35。让我们在时间轴上看一下。
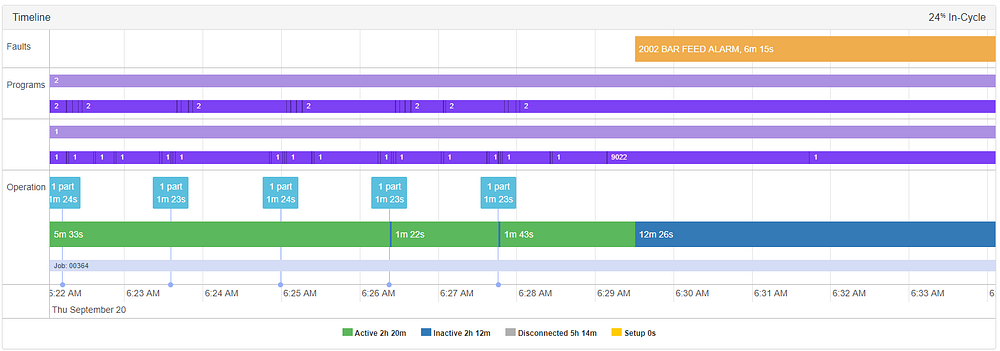
深入到主分量空间,我们看看它是什么样的。
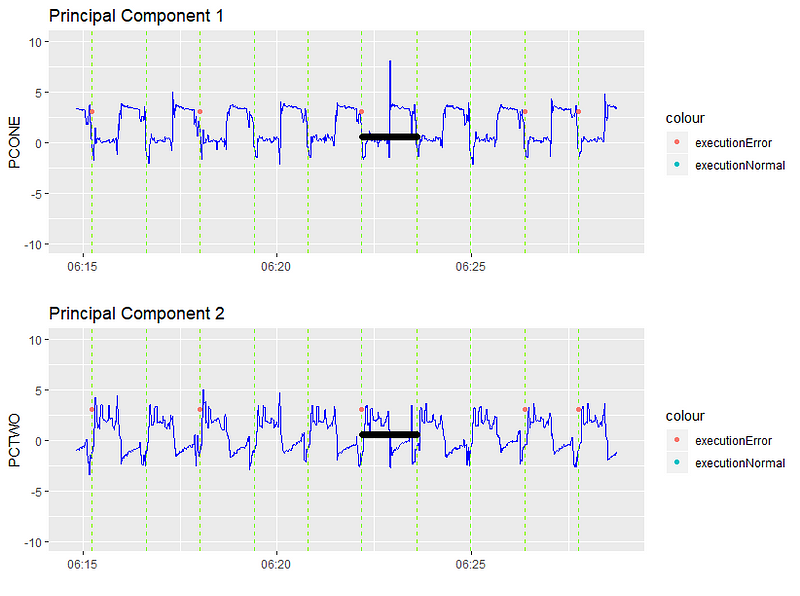
异常点用黑色突出显示。我们可以清楚地看到第一个主成分的峰值。让我们更深入地研究实际信号本身,看看发生了什么。
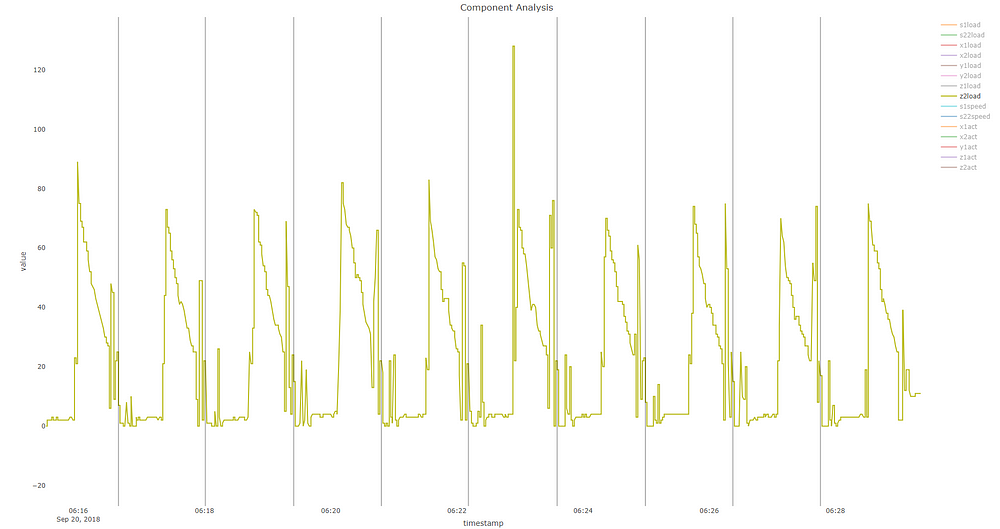
仅看Z2负载,似乎在6:22.56 AM有一个奇怪的扰动,明显的负载峰值从每部分80到这一部分超过120。除此之外,那段时间的电波模式也不同,你可以看到与该区域其他信号的明显不一致。当然,由于PCA的性质,很可能是其他信号没有显示在这个图表中,也以肉眼不明显的方式促成了这一点。
不出所料,我们还发现异常与警报同时触发。原始设备制造商内置警报,以提醒操作人员发生异常情况(我们的异常警报也是如此,所以它们经常重合也就不足为奇了)。这可能是一个好处,因为正如前面提到的,客户并不总是注意警报。一个警报+异常可能需要更多的注意,特别是如果每天有几十个lay警报。
这些报警异常对,表明机器操作相当不同,也可能比程序性报警更严重。在下面的例子中,一个异常在上午11:29被触发,与“barfeeder循环时间超过”的警报相一致,当barfeeder到达它的材料结束时开始。
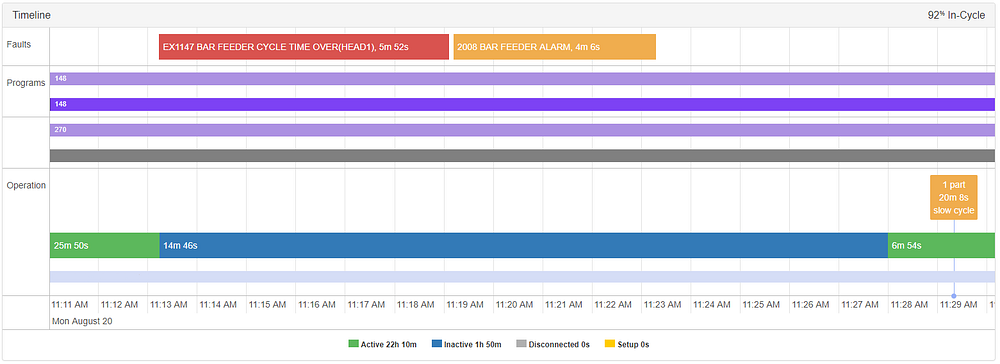

作为一个额外的副作用,我们还发现了一些内部bug,它们在我们的机器上表现为异常。在下面的例子中,我们发现了一个奇怪的实例,在这个实例中,机器实际上是活动的,而技术上它被标记为“非活动的”。这导致机器记录了在凌晨1:39创建的部件的异常。
这是因为我们只在机器处于激活状态时将数据读取到异常检测中,并且在看到截断的部分签名时触发异常。在确认机器在我们的原始数据流中确实是活动的之后,我们能够快速地查明并纠正错误,即我们的数据管道有时会放弃观察结果.
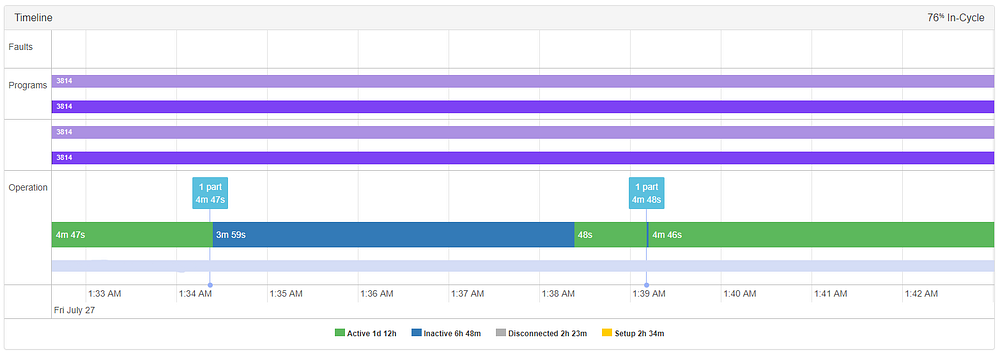
并不是所有的工具故障都有异常发生,也不是所有异常都与工具故障同时发生或之前发生。在这种情况下,“安全开关未锁”警报会被触发,因为操作员在启动机器之前没有将门完全关闭,并在下午12:59出现异常。作为一项自动安全预防措施,当发生这种情况时,机器保持不活动。虽然这不会妨碍运营,但楼层经理可能想知道这种情况何时发生(特别是如果这种情况反复发生),以鼓励更好的安全措施.
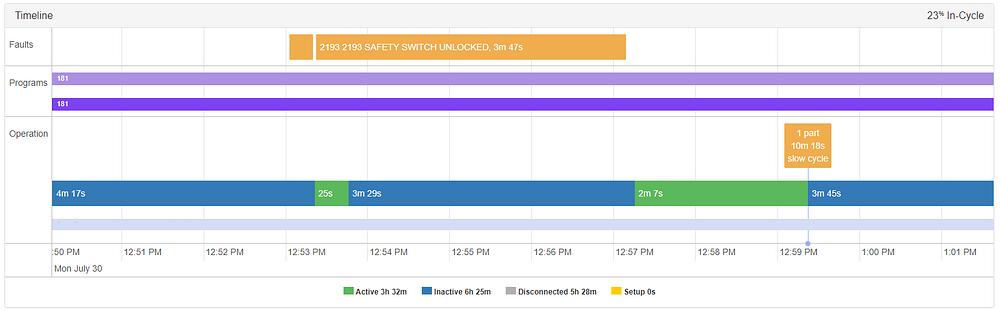
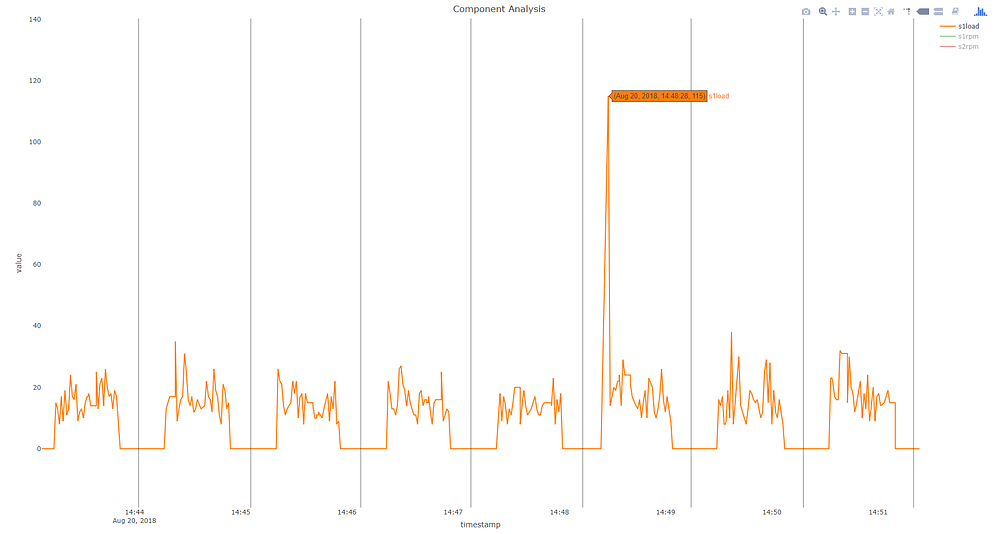
一如既往,有边缘案例不会落入我们为系统设计的范围内。在下面的例子中,在2:49触发异常,似乎没有押韵或理由。
然而,在更深入的调查之后,我们发现在这个部件创建周期中有一个s1load(主轴1load)峰值。这个峰值表明机器在额定负载的115%下运行,足以触发部件签名水平上的显著差异。在这种情况下,它是在这台机器的正常操作范围内,没有造成伤害或污染。
当我们从客户那里收集验证数据时,我们可以调整算法,使其对“有用的”异常更加敏感,而对多余的异常不那么敏感。反馈应该开始精确指出时间序列的哪些属性指向更有趣的异常。我们还可以进行A/B测试,向特定客户发布不同版本的算法,看看是否能获得更多好评。随着时间的推移,微小的改进可能导致显著的精度增益。
在未来,我们计划将机器学习与“基于规则”的领域知识异常过滤器相结合,以排除我们知道不感兴趣的情况。在不久的将来,我们将发布一个后记和更多工具故障的例子。
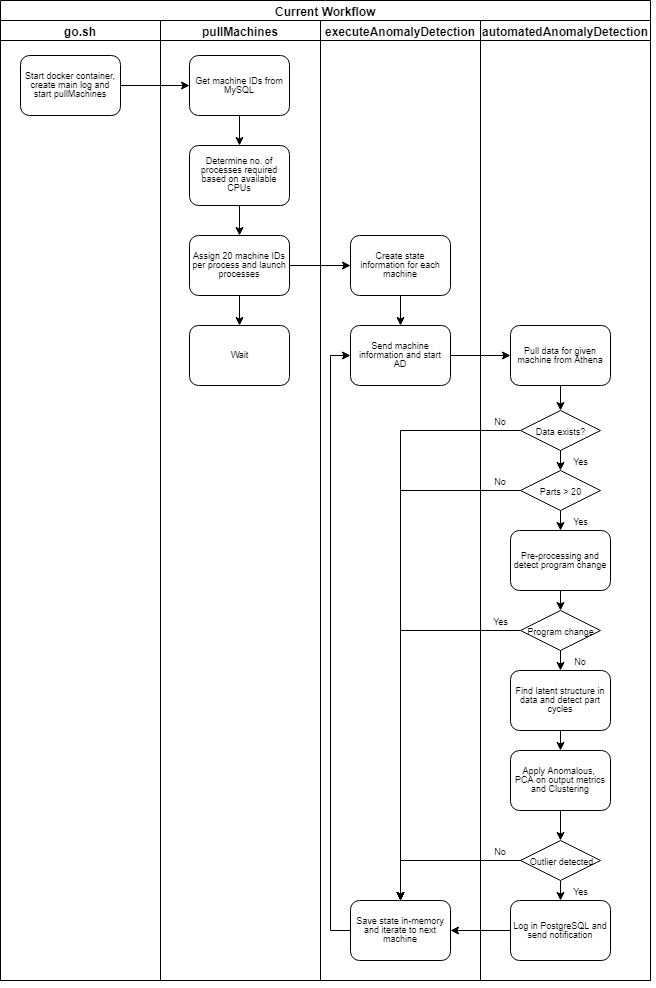
对于我们的试点,我们决定简单地对用于数据清理和集群的R脚本进行dockerize。这些脚本完成了本博客第2部分和第3部分中描述的所有繁重工作,我们只需要将它们包装在一个容器中,并进行一些自动化更改,使它们在生产中完全发挥作用。
该程序在生产中回顾并查询过去6小时的数据,检测部件周期并建立正常行为的粗略区域。一旦识别出零件周期,我们就可以连续查询数据并实时检测异常。检测到异常后,记录异常部分并发送短信给运营商,并在客户的主页上生成事件。
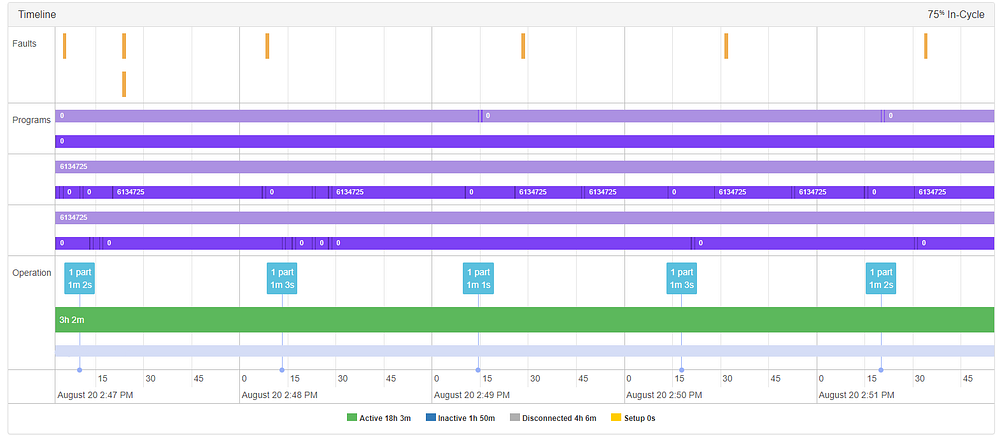
当我们收集一个“program_code”字段,表明哪个G-code程序正在运行时,该算法还具有检测一个新的部件类型正在启动的能力。切换程序将清除异常云并重新启动整个过程。
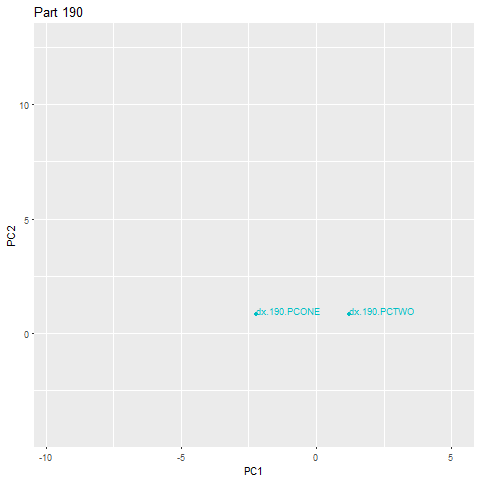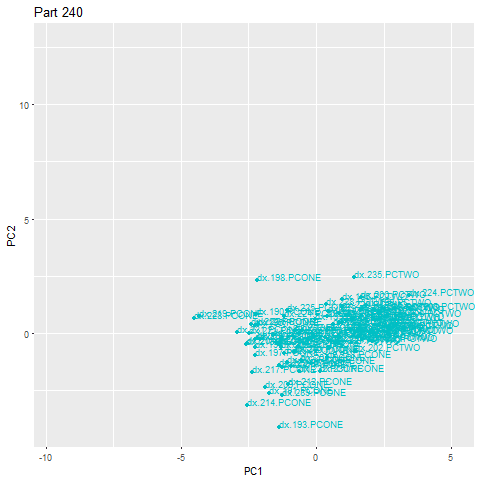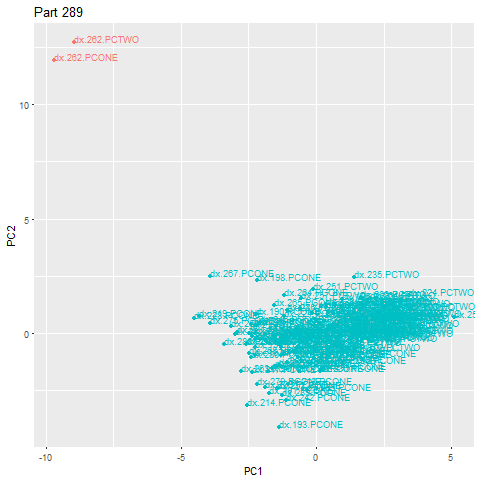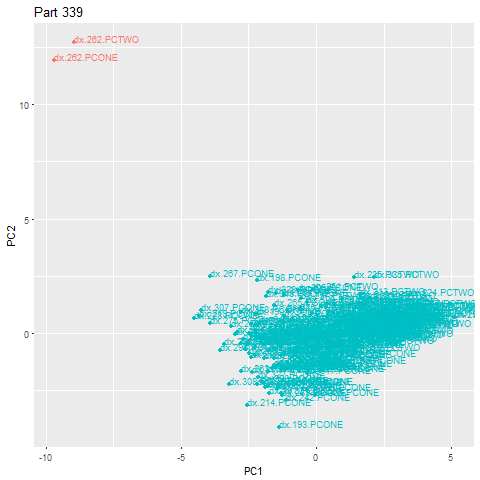
在下面的加速示例中,第262部分是一个异常,落在主云之外。一旦识别出异常值,就会立即触发警报。
我们将所有这些都封装在另一个脚本中,该脚本从数据库中提取机器ID,并将它们捆绑到15-20台机器的小组中。每个小组按顺序运行他们的15-20台机器,并将整个过程应用到每台机器上。这做在接收方收到警报时引入一些延迟,但仍然允许我们完整地记录和诊断异常,以便进一步调优(这是我们试点的最终目标)。
我们用Bash脚本触发这一切,它接受调整异常检测参数的参数。这在导频阶段特别有用,因为普遍需要在现场环境中进行高级计数调整。我们处理一个独特的问题,因为很难验证具有历史数据的异常 - 客户常常不记得当机器失败或经历奇怪的行为时。我们有一些例子来帮助我们进入,但我们没有收集过去的工具故障信息。
进一步说,我们知道警报何时发生,并能将它们与异常情况联系起来,但这不是一对一的。机器原始设备制造商和客户定义了这些警报,当机器出现故障时,由于安全原因,或当需要发出警告时,这些警报就会发生。然而,由于缺乏标准化,很难理清警报什么时候会导致停机,更不用说这个停机是由于警报还是其他原因。
供参考,对于对更多技术考虑因素感兴趣的人(或者如果您真的喜欢流程图),则概述了完整的产品化图。.
我们应该注意到,在前端,我们设计了一个UI,允许客户将每个异常标记为“异常和有用”,“异常和无用”,或“不是异常”,以收集验证数据,进一步完善我们的方法.
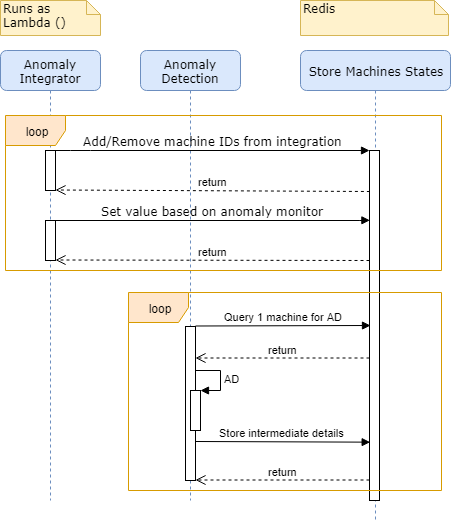
随着流程的发展,我们的计划是在增加健壮性的同时尽可能减少成本。我们计划用AWS Lambda函数代替dockerized的R脚本,它直接从我们的数据流中获取数据,并在那里完成所有的处理。不需要支付查询成本或EC2成本;处理速度会更快,可能失败的部件也会更少。这也将允许我们为不希望将其数据发送到云上的设施部署这种本地部署。
我们还添加了保存机器状态的详细信息的能力,以及我们希望在Redis中运行的计算机。
在完整的生产中,会有一组lambda,每个lambda对一小组机器运行异常检测。一旦lambda完成了微批处理,它将存储机器状态的详细信息。一旦恢复,它就可以立即将它与分配给它的机器的所有相应细节联系起来。
.
如果您有任何建议,请随时向我们发送消息!
感谢阅读我们关于异常探测的系列文章。想要了解更多关于MachineMetrics的信息,请访问我们:m.mangfpt24h.com
准备好授权你的车间了吗?
了解更多.svg)










评论