信号现在看起来整洁多了,类似于振动、语音或功率等典型信号数据。这是非常重要的,因为异常检测方法之前已经应用于这些类型的信号,生成这些信号的模拟扩展了我们的方法库。


在本系列的最后一篇文章中,我们讨论了为什么尝试检测机器上的异常行为很重要。在这篇文章中,我们将深入研究如何预处理和清理数据。
我们在许多机器上尝试了这种方法,但为了说明我们的观点,我们只列举一个例子。我们将从从我们的角度看什么加工过程开始。下面我们将绘制一台特定机器从晚上10点到上午9点的feed、速度和负载流数据。这台机器一直在生产同样的零件。
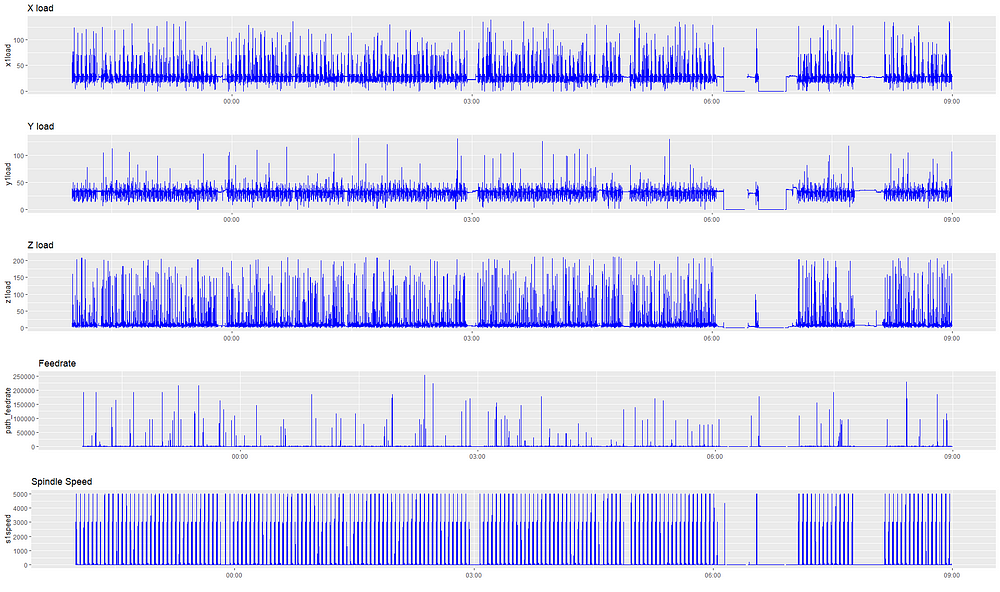
我们可以看到数据是有噪声的——我们不知道什么是相关的,也不知道在异常情况下我们要寻找什么。为什么信号是如此不规则和尖尖的,为什么信号中有间隙?如果机器正在制造相同的部分,为什么信号似乎没有规律?
这是因为MachineMetrics收集数据的方式。每900毫秒左右,我们打开一个“窗口”来检测指标的变化。如果有变化,我们会记录下来。如果没有,我们就不录任何东西。我们这样做主要有两个原因:
几乎可以肯定的是,每900毫秒就会改变一次,这意味着根据窗口打开的时间,制造的完全相同的部件看起来会不同。对于这个问题的解决方案,我们需要利用我们的领域知识和一些核心数据清理来获得可用的信号。
如果我们尝试对这些信号进行异常检测,而不清理它们,那么检测到的异常是没有意义的。我们用时间序列anomalize将结果打包并绘制在下面。Anomalize单流异常检测。异常表现为黑点,可以在不同的信号中发生在不同的时间。
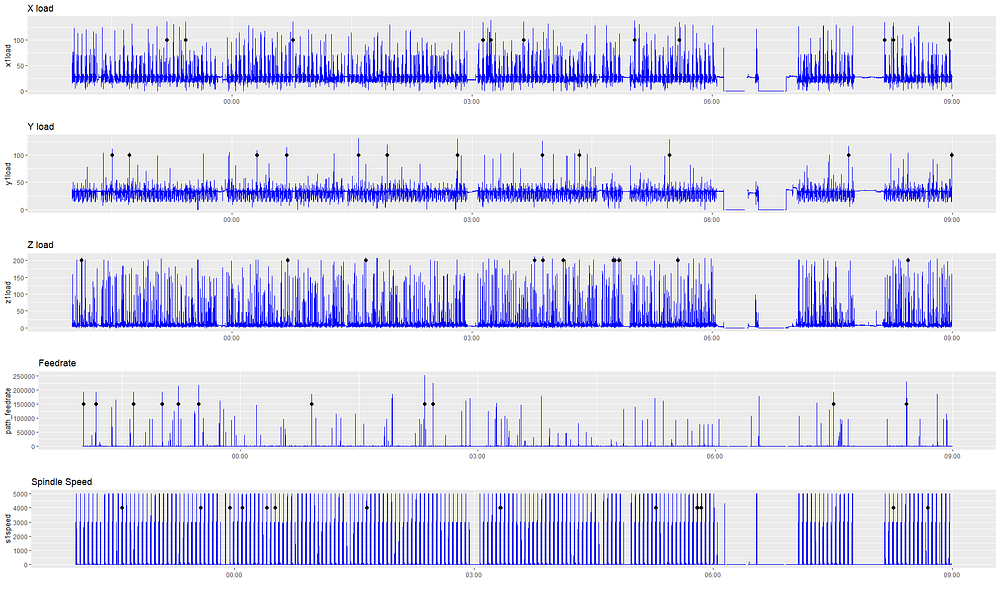
虽然其中一些信号在肉眼看来像是异常值,但探测到的异常实际上并没有什么用处。它们并不能显示出真正不寻常的行为,因为它们更多的是我们数据收集过程的产物。所以,是时候亲自动手处理数据了。首先,我们将解决停机(间隙)的问题。然后,我们将讨论如何平滑采样频率问题。
移除非活性序列
与这些数据混杂在一起的是大量的停机时间。停机时间包括操作员停机时间(凌晨3点零食,换班)和机器停机时间(内置冷却时间,工具更改,在本例中,我们将解码两个异常)。
我们的第一步是找出零件是什么时候制造出来的以及制造一个零件需要多长时间。我们并不真正关心当机器没有积极工作时是否会有定期更换刀具的情况,我们也不希望算法在加工过程中将此作为异常处理。
我们的第一步是过滤掉信号(我们关心的序列)和噪声(不相关的序列)。我们还希望确保我们不会从数据中排除真正异常的行为。
为了使这更容易,MachineMetrics收集一个“part_count”字段,该字段在零件加工完成时递增。我们通过进入机器的两个关键部件来捕捉这个磁场:

2.在其他类型中,我们可以接入机器的可编程逻辑控制(PLC),其中包括用G-code (CNC编程语言)表示零件完成的信号。
让我们将part_count叠加在前面的可视化上,以查看部件创建周期是什么样子的。每条绿色虚线代表一个部分的创建。
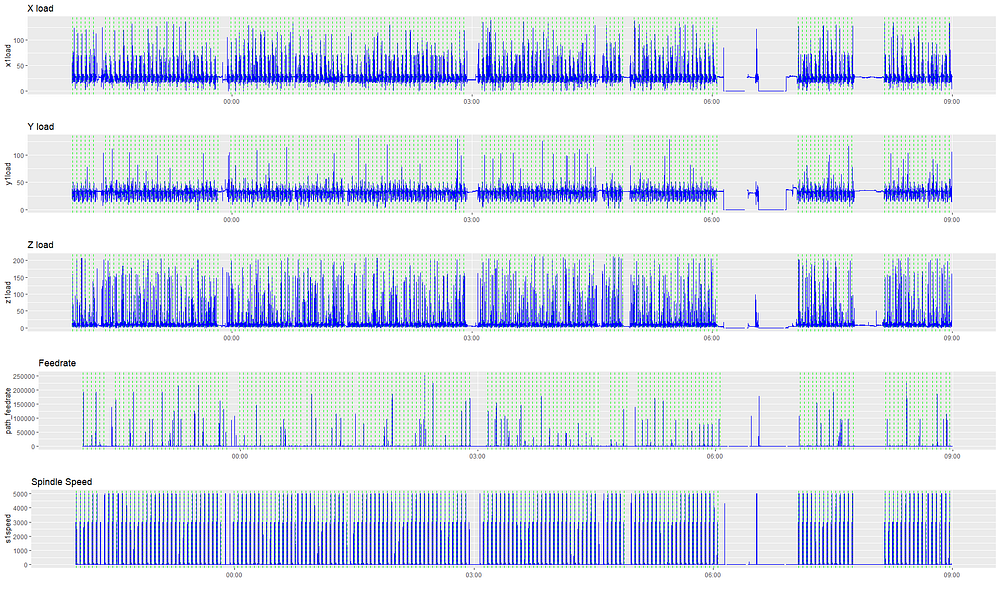
MachineMetrics还从控件中收集“机器状态”字段,该字段指示机器是否在主动加工。同样,这是通过敲击继电器或控制装置来收集的。
我们只想保存机器活动时的观察结果.在下面的图中,红色表示机器不活动的区域(或在设置中,等等)和我们消除观察的区域。
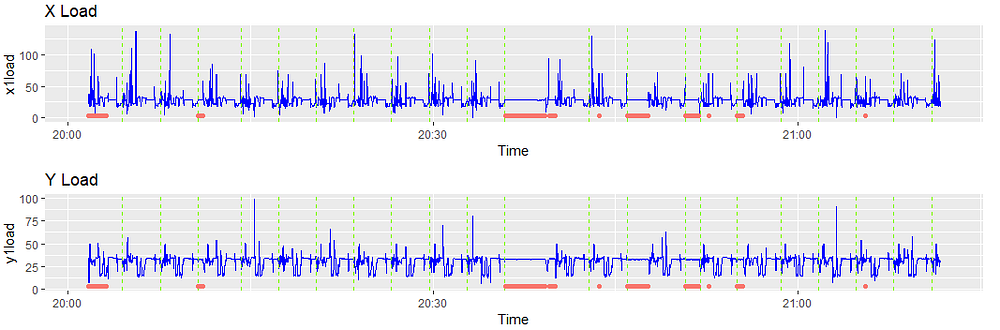
清洗后,信号如下所示。注意时间尺度的变化,因为移除时间序列中的观察结果将其转换为一个向量。
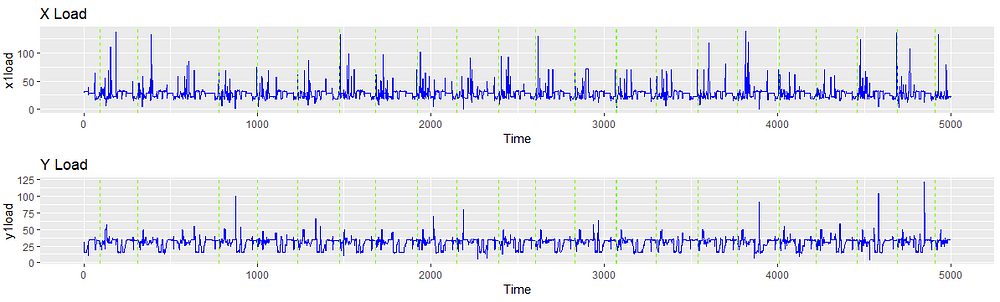
信号现在看起来整洁多了,类似于振动、语音或功率等典型信号数据。这是非常重要的,因为异常检测方法之前已经应用于这些类型的信号,生成这些信号的模拟扩展了我们的方法库。
加工过程潜在结构的检测
在从机械师的面试中收集反馈后的关系在负载之间,位置,主轴转速和进给率通常是看的关键因素。例如,如果速度、进给量和负载同时降为零,这就无关紧要了五月仅仅表明机器正在休息。然而,如果机器继续给材料,但负载下降到零,这是一个问题,意味着一个更深层的问题在手边。或者,如果轴的位置继续在它们的常规路径上,但它没有更多的负载,这可能意味着工具钻头折断了。

结果表明,尽管存在窗口测量误差,但由于涉及到的观测量的数量,在正常部件签名上的关系在很大程度上保持相同。随着时间的推移,普通零件会有类似的特征,尽管特征看起来的范围会更大。
我们需要找到一种有意义的方法来测量所有这些信号之间的相关性或关系,并将它们提炼为一个或两个组合信号,包括所有的馈电、速度、负载和位置。
我们求助于一种叫做主成分分析(PCA)的方法,将我们的许多信号提取为两个代表所有信号的信号。PCA采用多维矩阵,并通过捕获大多数方差的方向将其提取为“主成分”。例如,如果数据集的70%的方差可以在一维中捕获,而95%的方差可以在二维中捕获,那么通过消除所有其他变量,我们只会损失数据中的5%的信息。直观地说,它保持了能够最好地表示数据的变量的组合,并且通常可以从这些组合变量中派生出意义,作为支撑数据集的隐含信息。
例如,一个数据集可能有四个变量——每个国家的工业生产、犯罪率、消费者价格指数和收入不平等指数。PCA可以确定两个主要成分捕获几乎所有的信息,第一个是工业生产和消费者价格指数的组合,基本上代表GDP(支撑两者的隐含变量),第二个是犯罪率和收入不平等的组合(隐含变量代表类似社会动荡的东西)。
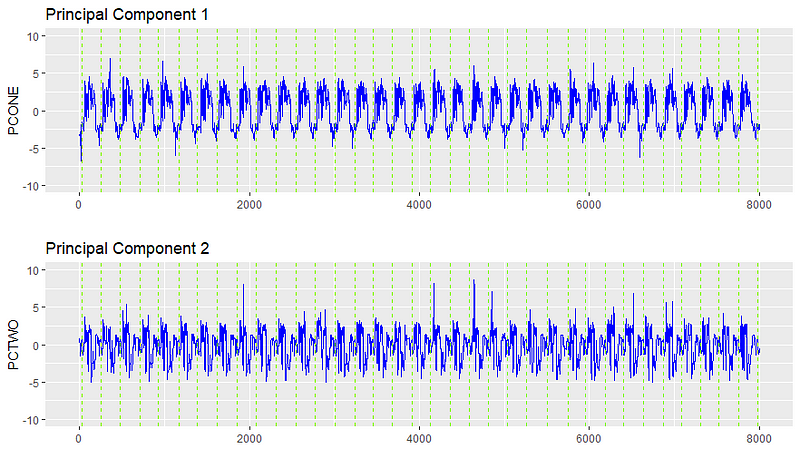
在我们的例子中,多维矩阵是所有位置、进给量、速度和负载(这台机器的33个变量)的集合。我们将所有这些变量简化为两个主成分,从33个原始变量中获取重要信息。我们能够识别关系的解耦,因为当原始33个之间出现不寻常的关系时,主信号中的值将非常敏感。

在找到潜在的信号后,我们可以把它们画出来,看到实际上有一个相当一致的信号。有了这个清理过的信号,我们可以开始执行更多异常检测的繁重工作。
准备好授权你的车间了吗?
了解更多.svg)










评论