在第1和第2部分中,我们讨论了在机器上检测异常行为所涉及的业务问题和预处理。在这篇文章中,我们将介绍一些创意数据争吵和聚类方法。这件作品在自然界中比其他人更为技术。
隔离部分签名和创建转换
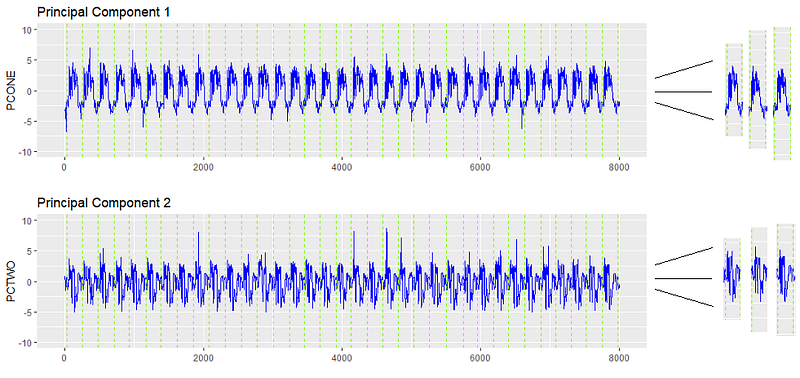
一旦我们有了清晰的信号,我们需要将该信号分解成各个独立的部件,即零件加工签名。每一个零件的加工特征代表被加工的一个零件,以及附加在该零件上的相应位置、进给、速度和载荷。
我们获取每个签名,并将它们挨个排列,创建一个表,其中每个“变量”都是创建的唯一部分及其附属数据。
确定部分签名的潜在结构
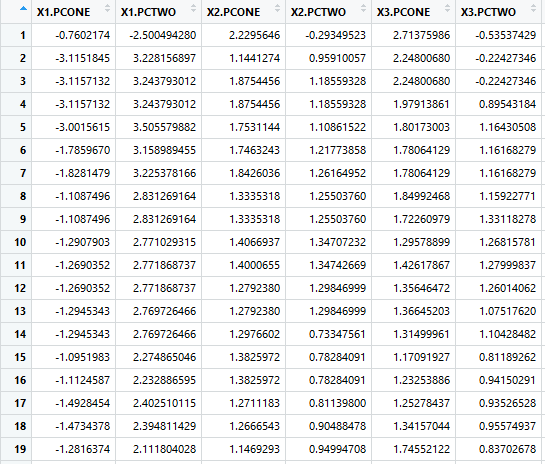
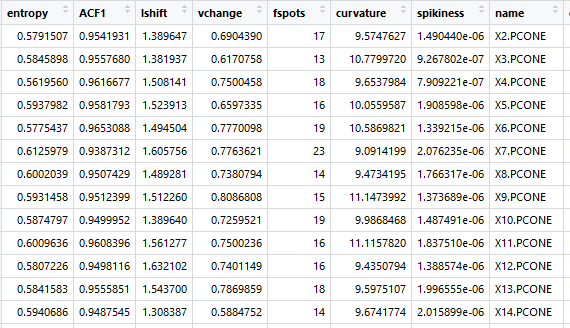
对于我们的下一步,我们转向罗克·赫恩德曼及其异常 包来检测每个变量的潜在结构。这背后的原因是,每个签名的原始值太不稳定,不能相互比较,即使通过滚动平均或其他转换来平滑它们。因此,我们必须找到另一种方式以更稳定的方式表示这些签名。Hyndman确定了时间序列的几个关键指标,这些指标反映了它们的内在品质。我们为这个用例选择了最相关的,下面用非技术术语概述了它们。这些是用来量化每个部分签名的内在因素。
熵:衡量您系列的白噪声是多少。
一阶自相关:一阶自相关是对时间序列中序列元素相关性的度量。用外行人的话来说,它衡量的是如果你知道级数中的前一个元素,那么级数的可预测性。这是相关的,因为异常序列通常显示非常不同的自相关函数与非异常序列。从本质上说,这是系列随机性的另一种衡量标准,对于异常系列,随机性通常是极高或极低的(如果机器的行为异常,随机性可能非常低,如果存在异常重复或可预测性,随机性可能非常高)。
级别换档:给出窗口的系列中滚动装置的最大变化。适合检测机器经历度量突然变化的异常。想想指标突然从一个级别跳到另一个级别。
方差变化:该系列滚动方差的最大变化。很好地检测异常,在机器经历突然变化的方差。想想看,当暴风雨过后,大海突然变得平静,或者当一台原本嘈杂的机器变得异常安静时。
曲率:告诉你零件的特征有多“弯曲”。值是二阶(x²)多项式拟合级数时的系数。相关的原因是由于加工的周期性,部分循环似乎有一个曲率,曲率的值在非异常曲线中是相似的。
尖顶性:拟合线性曲线时残差的方差。被称为“尖刺”,因为有更多尖刺的序列有更高的残差方差。
平坦的斑点:使用离散化的系列中的扁平点数。一个代理'机器挂起'。擅长检测机器摊位或滞后。
每个部分签名现在由这七个维度表示。基于这些属性检测异常,致力于整个时间序列。结果表看起来像以下,每个签名都蒸馏到这些特征。每个部分签名都是一行。
使用PCA将潜在特征投影到2D平面上
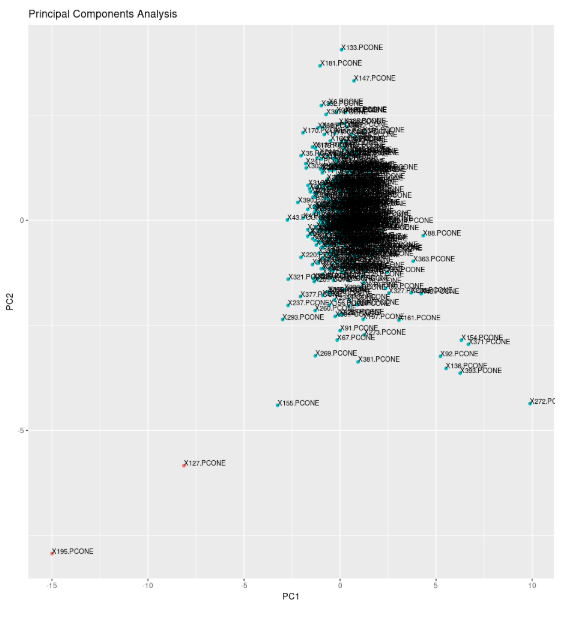
一旦我们获得了这些指标,我们将PCA应用于这七个维度,将它们减少为两个主成分。然后我们在二维散点图中绘制两个主分量。
我们只能通过以上的剧集来看看,存在部分群体的中央集群,郊区的一些分散的签名和某种方式远远偏远。那些“远离”的人是我们的异常。稍微截止的稍微截留的可能是捕获我们的测量误差,或者与正常加工活动的微小偏差,这可以包括由于环境条件而具有较小的载荷或主轴速度的场景。
我们为什么不采取转型?
还应该注意,我们测试了多个我们的数据转换,包括采用日志,滚动装置,滚动标准偏差和第一个衍生物。我们发现只是采取非转化的签名是检测异常的最有效的方式。我们定义最有效的是分离2D PCA空间中的其他点大部分的真实异常。这也是理论上的意义上,如
该系列的日志在每个系列中达到尖峰,可以排除关键信息
滚动方法做同样的事情,并删除被检测到的关键特征异常 包裹
滚动标准差在放大与方差相关的属性时可能会忽略重要的特征,这可能不是我们想要的
第一个衍生物可能强调签名的变化相对较小,因此混淆了签名的真实性质
使用聚类识别异常点
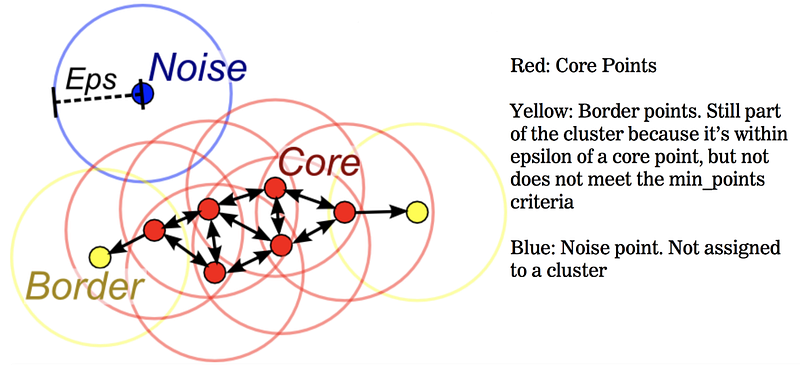
我们当然可以观察到离群值,但是使用集群是一种标准的方法来确定什么时候是离群值。我们使用一种称为DBSCAN的算法,它通过在每个点周围画一个圆,并在其周围寻找其他点来检测聚类。DBSCAN需要两个关键参数——“epsilon”,这是一个围绕每个点绘制的圆形区域,以确定集群的邻域,以及“最小点阈值”,这是必须落在该邻域的点的数量,它才被认为是一个集群。
下面是DBSCAN的示例。“核”点被认为是不异常的,“边界”点,在圆的边界上也是不异常的。然而,在中心区域之外的“噪声”点完全是异常的。
确定epsilon.
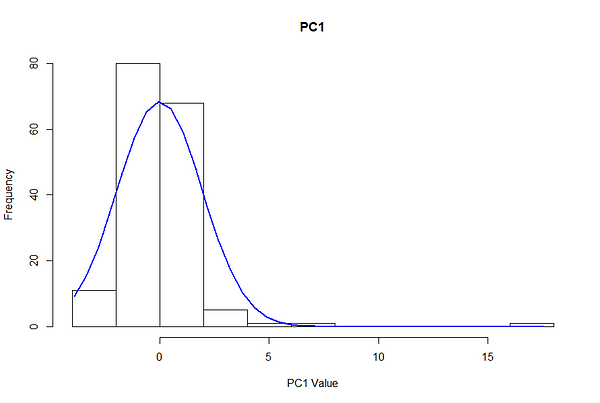
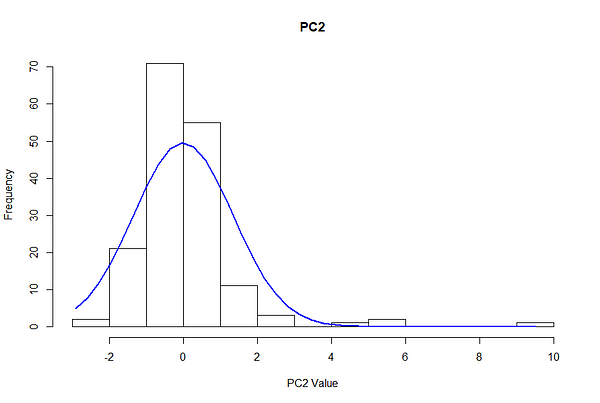
调整过程需要查看数据的分布和选择分离少数点的参数,同时不完全排除异常。为了获得epsilon的粗略数量级,我们应该使用该特定方案作为大多数情况的示例,为主成分1和主成分2的分布绘制分布。
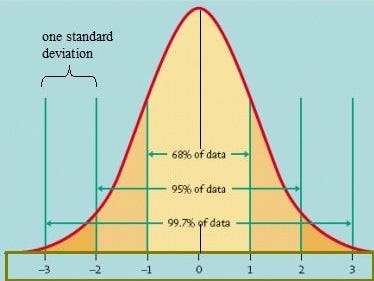
由于定心,主组件大致分布为零和标准偏差为1.5。在正常分布中,68%的观察结果包括在一个标准差,95%,三个标准偏差中,三分之二和99.7%。
资料来源:我1995年的数学教科书
这意味着给定1.5个PC的标准差,68%的观测值落在-1.5和1.5个PC之间,95%落在-3和3之间,99.7%落在-4.5和4.5之间。
我们知道,排除离群机器,MachineMetrics客户的平均报废率(包括人为错误)为~1/1000个零件,成功率为99.9% (MachineMetrics客户共制造3.27亿个零件,报废224k个)。虽然这看起来可能很高,但我们应该记住,我们的客户大多是较小的机械商店,可能没有大量的相同的部分正在制造。此外,我们的客户中有很大一部分是工作车间,他们为其他公司生产临时的、一次性的部件,这使得他们没有那么多时间来完善制造过程,从而留下了更多的出错空间。
MachineMetrics跟踪每种由机器制作的一部分,我们都可以连接到,让我们访问有关数据挖掘目的的唯一数据集
在正常分布的情况下,99.9%的观察结果在3个标准偏差范围内下降,这在我们的案例中是主要成分值中的±4.5单位。In consideration of the fact that precision (preventing false positives) is more important than recall (capturing all the anomalies) when first piloting this method, we set our epsilon threshold to be 4 standard deviations away, i.e. points must fall 6 units away from the central cluster to be considered an outlier. We consider precision more important because customers may choose to ignore the notifications if too many are given, and we want to avoid creating unnecessary panic*.
*此部分仍处于飞行员,参数可能会有所变化
确定最小点阈值
最小点阈值设置必须聚集在一起的最小点数,以便它被视为自己的独立集群,而不是异常值点。这在实际上没有异常的情况下,这可以是有用的,而是偶然的延期改变或其他系统但正常的差异。在这些情况下,机器可以在短时间内重置为正常状态。我们将此阈值定义为10分。
因此,我们将群集定义为至少十个点,εAton半径的大小为6个单位。任何落在6个单位的主要云端,都有少于10分,附近是一个异常。在这种情况下,我们检测到两个异常,对应有两个具有“异常值”加工签名的部分。我们可以识别在制作这些部件时,并且在机器表现出异常行为时,根据机器的时间编写与它们相对应的时间。
验证异常部件
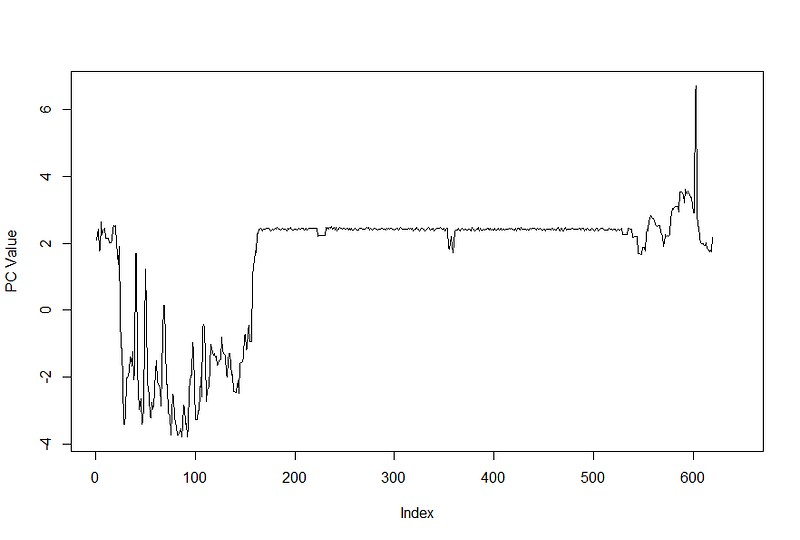
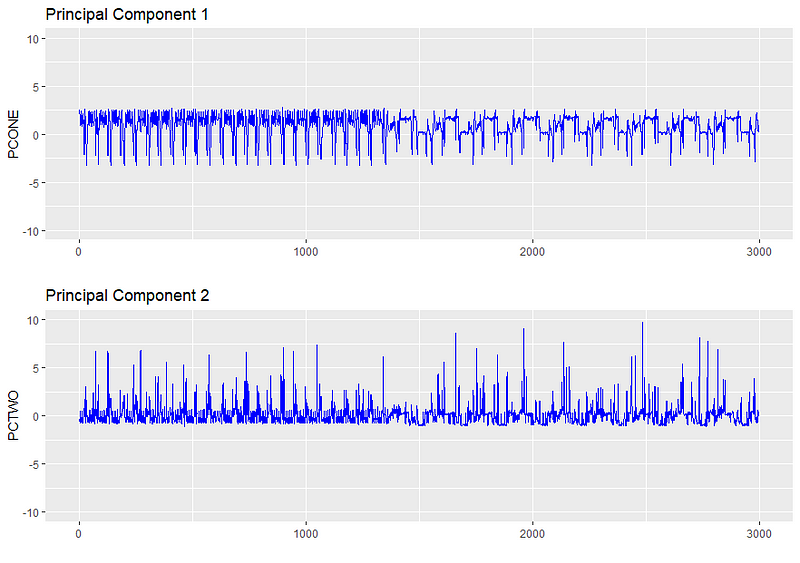
第127部分被检测到异常,在3:04至3:07之间创建。让我们来看看签名的样子。
正如我们所看到的,部分签名显然有所不同。在这种情况下,机器悬挂几分钟,重置自身,然后继续加工活动。虽然这次没有立即后果,但操作员被警告到这一点,并采取了进一步的措施来调查意外挂起,因为它可能导致未来工具失败。
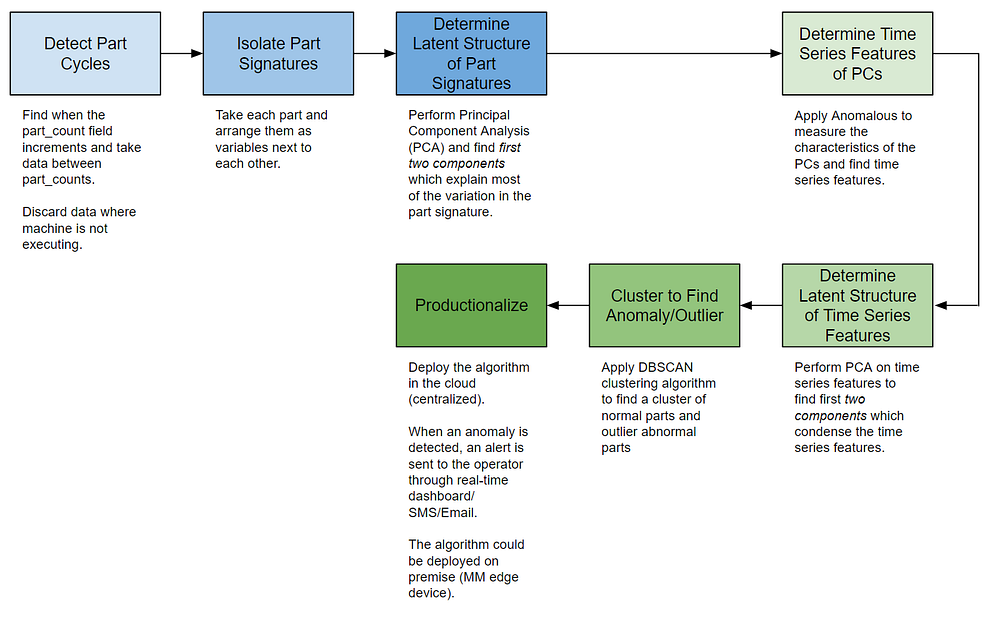
总结的步骤
在前几篇博文中我们已经讨论了很多内容。为了帮助总结所有内容,下面提供了一个流程图,以便更容易地理解这个过程。在本系列的最后一部分中,我们将介绍产品化。
替代用例
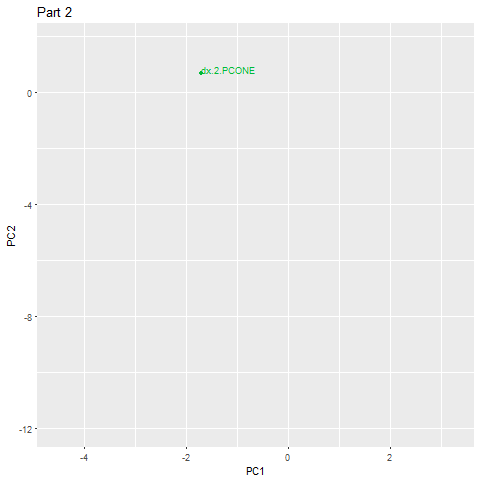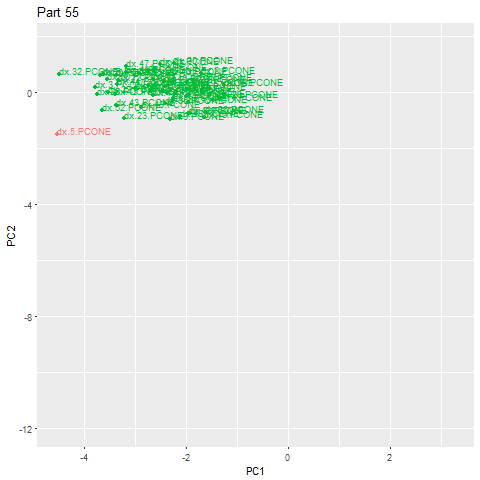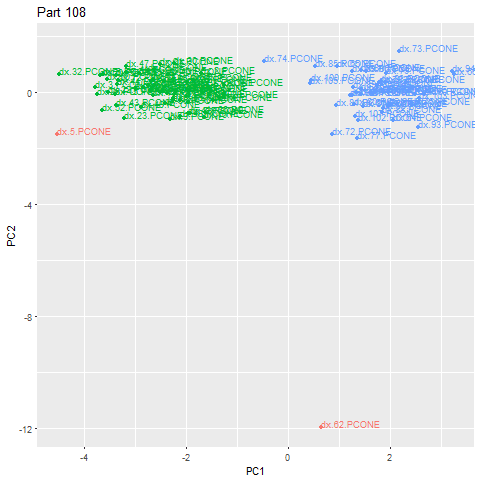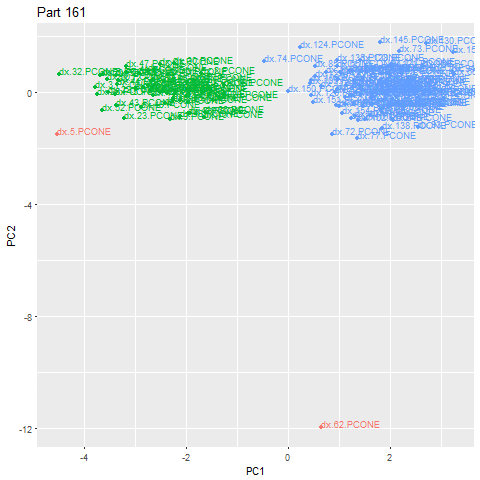
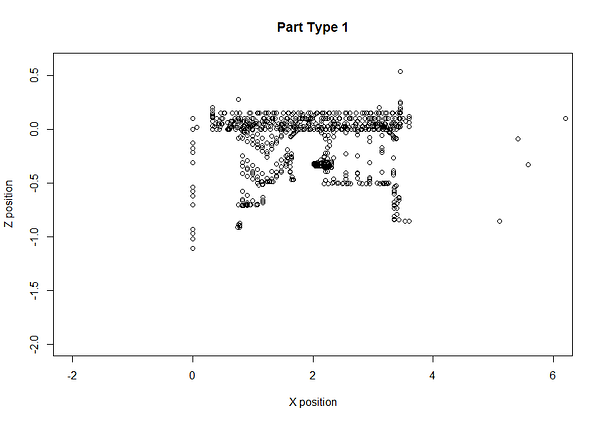
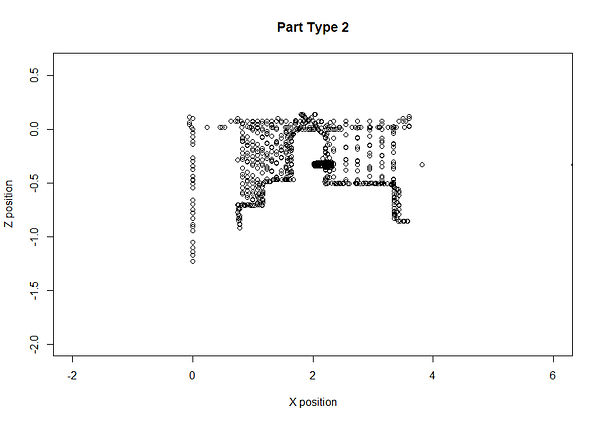
该方法的替代用途是检测制造改变的部件。使用相同的步骤,并将epsilon调整更适合这种情况,我们可以检测零件签名在结构上不同并形成另一个群集。在下面的示例中,我们可以看到第62部分有零件变化(由于实际的转换过程,该部分本身是异常的,但我们可以添加额外的规则来排除异常)。绿色云是一种类型的部分,蓝色云另一个。这使我们可以自动对客户进行分类。
GIF已经加速了效果。零件实际上是在大约83秒的周期内创建的
我们可以回顾并看到,当一个新的部件类型被制造出来时,部件签名的特征确实看到了一个显著的变化。
在转换期间部分签名的放大视图
我们验证了我们数据库中的地面真实数据,并确认此时有一种新型的部件。由于Machinimetrics轨道和存储工具位置,我们甚至可以绘制该部分来确定这一点。

.svg)


评论